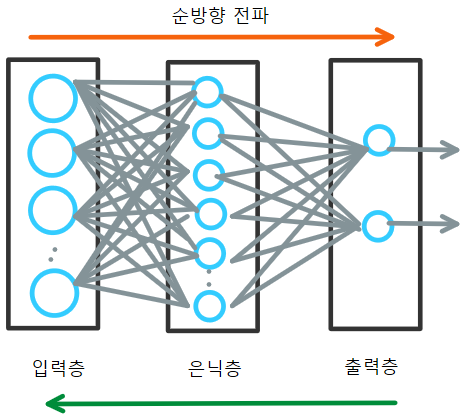
지도학습은 학습데이터(Training data) 와 검증데이터(validation data) 그리고 테스트데이터(test data) 로 구성되어 있다. 학습데이터를 통해 특징을 추출하고 model을 만들고 검증데이터로 모델이 잘 만들어졌는지 확인할 수 있다. 그리고 최종적으로 이 모델이 잘 만들어진 모델인지 테스트 데이터를 통해 그결과를 확인할 수 있다.이때, 뉴스데이터를 예로 들자면 뉴스의 카테고리(정치,문화,경제 등등..) 가 없는 뉴스기사를 데이터로 이용하고 이를 분류한다면 예측률이 매우 안 좋다. 반면 카테고리가 있는 뉴스기사를 데이터로 이용한다면 예측률이 좋다. 이 둘(카테고리가 있는 뉴스+ 카테고리가 없는 뉴스 데이터) 을 섞으면? 더 좋다! 그렇다면 이때 카테고리가 있는 뉴스와 없는 뉴스 한..