종속변수: 독립변수의 특정한 값에 따른 그의 값을 예측하고자 하는 변수
독립변수: 다른 변수에 영향을 주고 그 변수의 값을 예측하려는 변수
회귀 분석이란?
종속변수, 독립변수 사이의 함수적 관계를 기술하는 수학적 방정식을 구하는데 사용된다.
식은 독립변수의 값이 주어질 때 종속변수의 값을 추정하거나 예측하는데 사용된다.
서로 영향을 주고 받는 상관관계를 갖는 두 변수 사이의 관계를 분석하는 것이다.
python 에서는 대표적으로 sklearn 패키지에서 Linear regression 회귀분석을 위한 함수를 제공한다.
산포도란?
보통 X축:독립변수 / Y축: 종속변수를 설정하고 각 변수의 값을 나타내는 점을 도표로 나타낸다.
회귀분석 할 때 먼저 두 변수 사이의 관계를 대략적으로 알아보기 위하여 산포도를 그린다. (=산점도)
이것은 두 변수간의 관련성 및 예측을 위한 상관분석이나 회귀분석을 할 만한 자료인지를 미리 알 수 있게 한다.
단일선형회귀모델을 가정해보면,
1) 하나의 종속 변수와 하나의 독립변수를 분석한다.
2) 독립변수 X의 각 값에 대한 Y 의 확률분포가 존재한다.
3) Y의 확률분포의 평균은 X 값이 변함에 따라 일정한 추세를 따라 움직인다.
4) 종속변수와 독립변수 간에는 선형 함수 관계가 존재한다.
- 회귀 계수 추정 : 수집된 데이터 (산포도)에 가장 적절한 회귀 직선을 구하는 것 -> 최소자승법을 이용하여
- 최소자승법: 잔차를 자승한 값들의 합이 최소가 되도록 표본 회귀식의 a와 b를 구하는 방법, 측정값을 기초로 해서 적당한 제곱합을 만들고 그것을 최소로 하는 값을 구하여 측정결과를 처리하는 방법 , 자료들을 표시하는 각 좌표들과 사이를 지나는 직선과의 수직적 길이를 가장 짧게 하는 방법을 찾기 위해, 각 수직적 길이를 제곱하여 합한 값을 최소화한다. 큰 폭 오차에 대해 더 큰 가중치를 부여 함으로서, 독립변수 값이 동일한 평균치를 갖는 경우 가능한 한 변동 폭이 작은 표본 회귀선을 도출하기 위한 것이다.
- 잔차 (Residual): 독립변수 X의 값이 주어질 때 표본 회귀선의 예측값과 실제값 사이에 표본 오차 때문에 발생하는 차이
파이썬 코드로 작성해보자면,
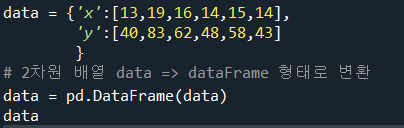
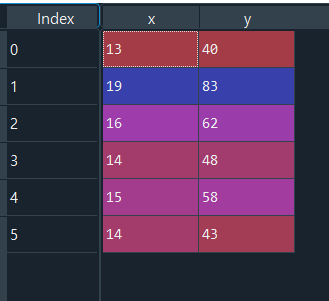
우선 데이터를 정의한다.
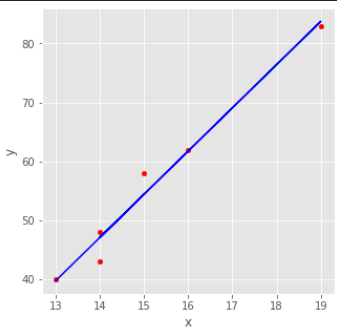
이제 데이터를 학습시키기!

학습시키기 위해서는 X,y 값을 입력해야하는데 이때 X값은 2차원형태로, y값은 기존 형태로 입력해야한다.
fit 함수를 이용하여 선형회귀모델 훈련을 실험한다.

선형회귀값 구하기

실제값 - 예측값 = 잔차
- 적합도 검증
위에서 본 표본자료를 사용하여 구한 표본회귀식이 종속변수의 값을 어느 정도 정확하게 예측할 수 있을까? 검증해보는 것
두 변수 값들이 표본회귀선 근처에 모여있다면? 잔차( 종속변수의 실제값 - 예측값) 가 줄어들어 예측 정확성이 높어진다.
이러한 적합도를 검증하기 위한 방법에는 1) 추정의 표준오차 2) 결정계수가 있다.
1) 추정의 표준오차는 표본들의 실제 값들이 표본회귀선 주위로 흩어진 변동을 측정하는 것이다.
(표준편차: 표본들의 실제 값들이 평균 주위로 흩어진 변동을 측정하는 것이다)
추정의 표본오차 값이 클수록 실제 값들이 표본회귀선 주위로 널리 흩어지고, 작을수록 실제 값들이 표본회귀선 주위로 모여들어 그 예측에 대한 정확도는 높아진다.
추정의 표준오차 식은 잔차(예측값 - 실제값) 들의 표준편차를 구하기 위한 식이다. 실제 값이 회귀식과 얼마나 떨어져있을까? 를 나타내기위해! 추정 표준 오차 계산 기준은 회귀직선, 절편과의 기울기의 두 통계량에 의해 결정된다
SSE: 오차제곱합

총변동: 총제곱합 (SST) = 회귀제곱합(SSR) + 잔차제곱합 (SSE)
SST: 실제 값들이 평균으로부터 흩어진 정도

SSR: 예측치와 실제값들의 평균 차이의 제곱합
2) 결정계수 : 결정계수는 0~1까지의 값을 가진다. 표본회귀선이 모든 자료에 완전 적합이라면 SSE = 0 , 결정계수는 1 이다.
결정계수를 구하는 식은 1-(SSE/SST) 이다. 결정계수의 값이 1에 가까울수록 예측 정확성이 높다.
리고 이런 방식으로 손실을 구하는 걸 평균 제곱 오차(mean squared error, 이하 MSE)라고 부른다. 손실을 구할 때 가장 널리 쓰이는 방법이다.


- 성능평가
1) 잔차 : 회귀분석 모델의 예측 값과 실제 값 사이의 차이
2) MSE (Mean Squared Error) : 평균제곱오차, 회귀선과 모델 예측 값 사이의 오차를 사용한다. 오차를 제곱한 값들의 평균이다.
손실을 구하는 이 외의 방법으로는 MSE처럼 제곱하지 않고 그냥 절대값으로만 바로 평균을 구하는 것도 있다.
선과 실제 데이터 사이에 얼마나 오차가 있는지 구하려면 양수, 음수 관계 없이 동일하게 반영되도록 모든 손실에 제곱을 해주는 게 좋다.
3) RMSE (Root Mean Squared Error) : MSE 에서 구한 값에 루트를 적용한 값이다.
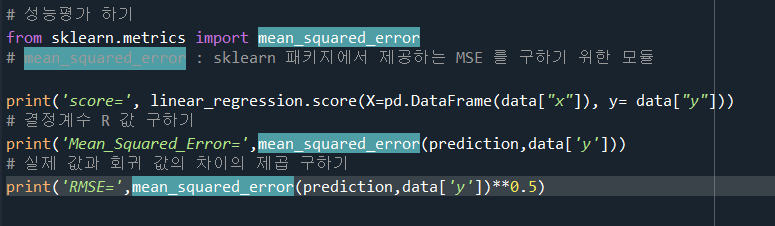
결국 선형 회귀 모델의 목표는 모든 데이터로부터 나타나는 오차의 평균을 최소화할 수 있는 최적의 기울기와 절편을 찾는 것이다!
'인공지능' 카테고리의 다른 글
| MLP 신경망 (Multi-Layer Perceptron) (0) | 2020.11.21 |
|---|---|
| CNN 알고리즘 (컨벌루션 네트워크) (0) | 2020.10.26 |
| 기계학습, 머신러닝이란? (0) | 2020.10.19 |
| 빅데이터란 무엇인가 (0) | 2020.06.02 |
| 파이썬을 이용한 머신러닝 ) 다중선형회귀분석 (0) | 2020.04.28 |